HashMap的加载因子连环炮
1.加载因子为什么是0.75?
很多人说HashMap的DEFAULT_LOAD_FACTOR = 0.75f是因为这样做满足泊松分布,这就是典型的半知半解、误人子弟、以其昏昏使人昭昭。实际上设置默认load factor为0.75和泊松分布没有关系,而是我们一个随机的key计算hash之后要存放到HashMap的时候,这个存放进Map的位置是随机的,满足泊松分布。
我们来看一下官方对这个加载因子的解释:
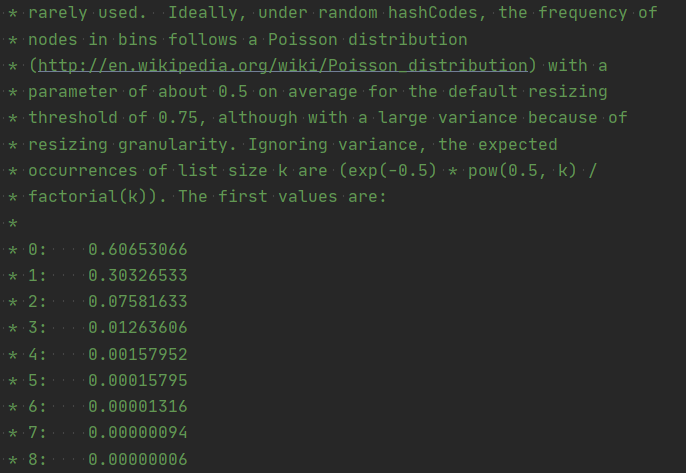
简单翻译一下:理想情况下,在随机hashCodes下,bin中节点的频率遵循Poisson分布(http://en.wikipedia.org/wiki/Poisson_distribution),默认调整大小阈值0.75的平均参数约为,尽管由于调整粒度而差异很大。忽略方差,列表大小k的预期出现次数是(exp(-0.5)* pow(0.5,k)/ * factorial(k))。第一个值是:
- 0:0.60653066
- 1:0.30326533
- 2:0.07581633
- 3:0.01263606
- 4:0.00157952
- 5:0.00015795
- 6:0.00001316
- 7:0.00000094
- 8:0.00000006
其他:少于一百万分之十
也就是说,我们单个Entry的链表长度为0,1的概率非常高,而链表长度很大,比8还要大的概率忽略不计了。
2. 加载因子可以调整吗??
可以调整,hashmap运行用户输入一个加载因子
public HashMap(int initialCapacity, float loadFactor) {
}
3. 加载因子为0.5或者1,会怎么样?能大于1吗
我们凭借逻辑思考,如果加载因子非常的小,比如0.5,那么我们是不是扩容的频率就会变高,但是hash碰撞的概率会低很多,相应的链表长度就普遍很低,那么我们的查询速度是不是快多了?但是内存消耗确实大了。
那么加载因子很大呢?我们想象一下,如果加载因子很大,我们是不是扩容的条件就变的更加苛刻了,hash碰撞的概率变高,每个链表长度都很长,查询速度变慢,但是由于我们不怎么扩容,内存是节省了不少,毕竟扩容一次就翻一倍。
那么加载因子大于1会怎么样,我们加载因子是10,初始容量是16,当桶数达到160时扩容,平均每个链表长度为10,链表并没有长度限制,所以,加载因子可以大于1,但是我们的HashMap如果查询速度取决于链表的长度,那么HashMap就失去了自身的优势,尽管JDK1.8引入了红黑树,但是这只是补救操作。
如果在实际开发中,内存非常充裕,可以将加载因子调小。如果内存非常吃紧,可以稍微调大一点。