是否了解字典树?
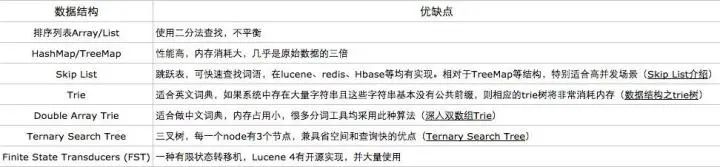
常用字典数据结构如下所示:
Trie 的核心思想是空间换时间,利用字符串的公共前缀来降低查询时间的开销以达到提高效率的目的。它有 3 个基本性质:
1)根节点不包含字符,除根节点外每一个节点都只包含一个字符。
2)从根节点到某一节点,路径上经过的字符连接起来,为该节点对应的字符串。
3)每个节点的所有子节点包含的字符都不相同。
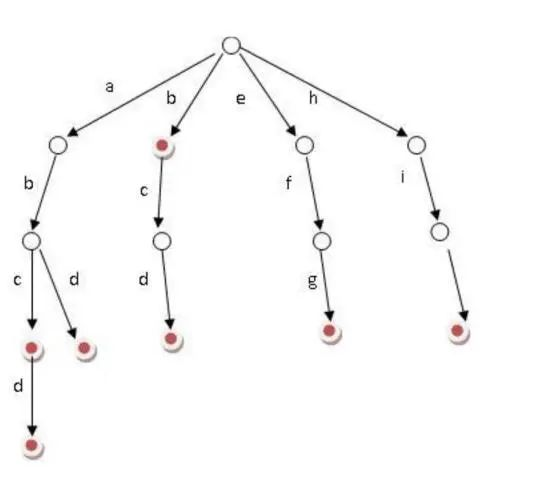
(1)可以看到,trie 树每一层的节点数是 26^i 级别的。所以为了节省空间,我们还可以用动态链表,或者用数组来模拟动态。而空间的花费,不会超过单词数×单词长度。
(2)实现:对每个结点开一个字母集大小的数组,每个结点挂一个链表,使用左儿子右兄弟表示法记录这棵树;
(3)对于中文的字典树,每个节点的子节点用一个哈希表存储,这样就不用浪费太大的空间,而且查询速度上可以保留哈希的复杂度 O(1)。