unordered_map、unordered_set 底层原理及其相关面试题
(1)unordered_map、unordered_set的底层原理
unordered_map的底层是一个防冗余的哈希表(采用除留余数法)。哈希表最大的优点,就是把数据的存储和查找消耗的时间大大降低,时间复杂度为O(1);而代价仅仅是消耗比较多的内存。
使用一个下标范围比较大的数组来存储元素。可以设计一个函数(哈希函数(一般使用除留取余法),也叫做散列函数),使得每个元素的key都与一个函数值(即数组下标,hash值)相对应,于是用这个数组单元来存储这个元素;也可以简单的理解为,按照key为每一个元素“分类”,然后将这个元素存储在相应“类”所对应的地方,称为桶。
但是,不能够保证每个元素的key与函数值是一一对应的,因此极有可能出现对于不同的元素,却计算出了相同的函数值,这样就产生了“冲突”,换句话说,就是把不同的元素分在了相同的“类”之中。 一般可采用拉链法解决冲突:
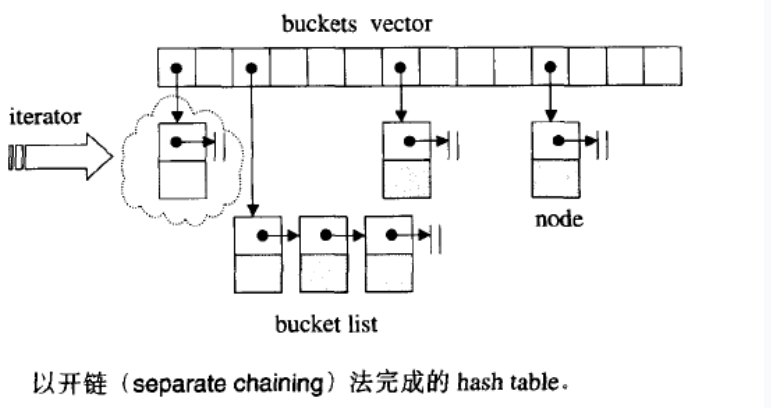
(2)哈希表的实现
(3)unordered_map 与map的区别?使用场景?
构造函数:unordered_map 需要hash函数,等于函数;map只需要比较函数(小于函数).
存储结构:unordered_map 采用hash表存储,map一般采用红黑树(RB Tree) 实现。因此其memory数据结构是不一样的。
总体来说,unordered_map 查找速度会比map快,而且查找速度基本和数据数据量大小,属于常数级别;而map的查找速度是log(n)级别。并不一定常数就比log(n)小,hash还有hash函数的耗时,明白了吧,如果你考虑效率,特别是在元素达到一定数量级时,考虑考虑unordered_map 。但若你对内存使用特别严格,希望程序尽可能少消耗内存,那么一定要小心,unordered_map 可能会让你陷入尴尬,特别是当你的unordered_map 对象特别多时,你就更无法控制了,而且unordered_map 的构造速度较慢。
评论(2)
不显图啊
已更改,不过好久没看评论了,,好像有点忘了,,